
[Data Science Project] Amazon Magazine Subscription Review Data Analysis: Topic Modeling Techniques on LDA, BERTopic, and LLM-based QualIT
Introduction
Topic modeling is a widely used language processing (NLP) technique for extracting latent thematic structures from unstructured text data, such as social media posts, news articles, or customer feedback. This project examines the application of various Topic Modeling approaches, including LDA, BERTopic, and a large language model (LLM), an enhanced method inspired by QualIT (Karpoor et al., 2024). Based on Amazon Magazine review data, this project performs Topic Modeling to extract keywords and cluster reviews by each characteristic.
How do LLMs Work?
LLM represents words using vector embeddings and learn to predict the next word in a sequence. During training, the model updates parameters to maximize the likelihood of correct predictions, a process known as self-supervised learning. Once trained, LLMs can:
-
Answer questions
-
Translate languages
-
Summarize documents
-
Write code or articles
Why are LLMs Important?
LLMs power generative AI, assist in customer service, support content creation, and are redefining knowledge retrieval and developer productivity.
Real-World Applications
-
Copywriting and marketing content
-
Customer sentiment analysis
-
Text classification
-
Code generation (e.g., GitHub Copilot, CodeWhisperer)
-
Conversational AI (e.g., ChatGPT, Alexa)
The Future of LLMs
LLMs are expected to evolve with:
-
Better accuracy and bias reduction
-
Multimodal training (text, image, audio)
-
Wider workplace automation
-
Smarter, more interactive virtual assistants
If you want more information, click this link here: LLM on AWS
Kapoor et al. (2024)
Topic modeling is a widely used technique for uncovering thematic structures from large text corpora. However, traditional topic modeling approaches have several limitations (explained later). They suggest a new type of topic modeling method, Qualitative Insights Tool (QualIT), that integrates large language models (LLMs) with existing clustering-based topic modeling approaches. Their method influences the deep contextual understanding and powerful language generation capabilities of LLMs to enrich the topic modeling process using clustering. This finding suggests the integration of LLMs can unlock new opportunities for topic modeling of dynamic and complex text data, as is common in talent management research contexts.
Research Gap
Most topic modeling approaches (e.g., Latent Dirichlet Allocation (LDA) struggle to capture nuanced semantics and contextual understanding required to accurately model narratives. They also fail to capture the contextual nuances and ambiguities inherent in natural language, as they rely heavily on predefined rules and patterns.
When conducting topic modeling in talent management research, the limitations of topic modeling make its development necessary. These include taking too much time (about 3 months per project) to sample participants, collect data, and analyze documents. Further, the lack of familiarity/expertise in qualitative research methods limits easy analysis or sharing of insights.
Methodology
The newly introduced LLM Enhanced Topic Modeling consists of multiple steps to generate the main topics, which are then used to determine subtopics from documents.
Key-Phrase Extraction
The LLM prompt can extract multiple key phrases from the document, depending on its content. Alternative methods (e.g., BERTopic) assume that each document only contains a single topic, when in reality, a document may contain more than a single topic.
Hallucination Check
Hallucination Check scores how well the key phrase aligns with the actual text.
\[C_i = \frac{1}{n} \sum_{j=1}^n \frac{V_{\text{input},ij} \cdot V_{\text{keyphrases},ij}}{\left\|V_{\text{input},ij}\right\| \cdot \left\|V_{\text{keyphrases},ij}\right\|}\]Where:
- ( C_i ) is the coherence score for the ( i )-th document.
- ( n ) is the number of dimensions in the embedding space.
- ( V_{\text{input},ij} ) is the ( j )-th dimension of the normalized embedding vector for the input text of the ( i )-th document.
- ( V_{\text{keyphrases},ij} ) is the ( j )-th dimension of the normalized embedding vector for the theme text of the ( i )-th document.
\[C_i = V_{\text{input},i} \cdot V_{\text{keyphrases},i}\]💡 Note: If the vectors are already normalized (i.e., have unit length), the formula simplifies to:
Clustering
They used a partitional k-means clustering algorithm to group the key phrases identified in the previous step. The aim of this step is to group documents into multiple clusters, each representing a collection of documents into multiple clusters, each representing a collection of documents with similar semantic content.
Clustering for Main Topics
This process creates the primary cluster and passes the key phrases of each cluster to another LLM prompt to distill a main theme from the grouped documents.
Clustering for Sub Topics
This process implements a secondary level of clustering within each primary cluster to uncover more specific subtopics. There are two advantages of this method. First, it reduces noise and the influence of irrelevant data, allowing the algorithm to operate on the distilled thematic essence of the documents. Second, this approach can avoid the need for manual data exploration and cleaning steps, such as stopwords or punctuation removal, as the LLm can extract only the most meaningful content from the documents.
However, there is a drawback to K-means clustering as it requires the number of clusters as a parameter to perform clustering. To address this drawback, they utilized the length of the data and calculated a Silhouette score to automatically determine the number of clusters.
\[s(i) = \begin{cases} \frac{b(i) - a(i)}{\max \left(a(i), b(i)\right)}, & \text{if } |C_T| > 1 \\\\ 0, & \text{if } |C_T| = 1 \end{cases}\]Where:
- ( s(i) ): Silhouette score
- ( a(i) ): The mean distance between a sample and all other points in the same cluster.
- ( b(i) ): The mean distance between a sample and all other points in the nearest cluster that the sample is not a part of.
Experiment
Dataset
The 20 NewsGroups dataset was pre-processed minimally: tokens, special characters, stop words, and tokens smaller than length 3 were removed, as well as tokens were lemmatized.
Model
Their LLM Enhanced Topic Modeling utilized Claude-2.1, with a temperature setting of 0, top_k of 50, and top_p of 0.
Evaluation
They used topic coherence and topic diversity to measure the performance of the experiment.
\[\text{in}(x, y) = \frac{\ln \left( \frac{p(x, y)}{p(x) \cdot p(y)} \right)}{-\ln p(x, y)}\]A score of 1 in topic coherence indicates a perfect association.
Results
For most of the topics, LLM Enhanced Topic Modeling outperforms both LDA and BERTopic in the 20 NewsGroups dataset in terms of TC and TD.
However, when the number of topics increases to 40 and 50, BERTopic minimally outperforms LLM Enhanced Topic Modeling in terms of Topic Coherence, but not for Topic Diversity.
Limitations and Future Work
Firstly, the runtime of the model is a significant constraint for large datasets; efforts should be made to reduce it to be more in line with BERTopic, which completes in approximately 30 minutes as opposed to the current 2-3 hours for our LLM Enhanced Topic Modeling.
While their method currently utilizes K-Means clustering, there is an opportunity to explore HDBSCAN.
Closing Thoughts
QualIT can surface both high-level topic insights as well as more granular subtopics from qualitative feedback data. QualIT’s approach produces more coherent and diverse topics compared to benchmark topic modeling techniques. QualIT can efficiently and effectively extract meaningful insights will become increasingly invaluable.
Data introduction
For this project, I utilized customer review data collected by Amazon, specifically focusing on magazine subscriptions. These reviews are rich in natural language content and highly suitable for testing topic modeling techniques.
Data sources
The dataset was obtained from the publicly available UCSD Amazon Review Dataset:
- UCSD Amazon Review Dataset:
https://cseweb.ucsd.edu/~jmcauley/datasets.html
- File used:
Magazine_Subscriptions.jsonl
Major characteristics of the data
-
Fields:
rating(float: from 1.0 to 5.0)title(Title of the review)text(main review body)asin,timestamp, and other metadata
-
Langauge:
English -
Document type: Free-text customer reviews
-
Structure: Highly diverse in tone, length, and writing style
-
Size: ~71,500 records
This variety in user-generated content makes the dataset particularly challenging and valuable for exploring different topic modeling strategies.
Data pre-processing
To ensure consistency across all models, a unified preprocessing pipeline was implemented. The main steps included:
-
Removing extra whitespace
-
Stripping emails and apostrophes
-
Filtering out non-alphabet characters
-
Converting all text to lowercase
Here’s the preprocessing function used:
import re
# Preprocess the text data
def preprocess_text(text):
text = re.sub('\s+', ' ', str(text)) # Remove extra spaces
text = re.sub('\S*@\S*\s?', '', str(text)) # Remove emails
text = re.sub('\'', '', str(text)) # Remove apostrophes
text = re.sub('[^a-zA-Z]', ' ', str(text)) # Remove non-alphabet characters
text = text.lower() # Convert to lowercase
return text
data['cleaned_text'] = data['text'].apply(preprocess_text)
- Tokenized using
gensim - Stopwords removed using
nltk - Lemmatized using WordNet Lemmatizer
LDA
What is LDA?
LDA (Latent Dirichlet Allocation) is a type of traditional topic modeling technique. It is a generative probabilistic model that operates on the principle that each document in a corpus is composed of a mixture of latent topics, with each topic being represented by a unique probability distribution over the vocabulary. This model learns the topic-world distribution by leveraging the co-occurrence patterns of words within the documents, allowing it to uncover the underlying thematic structure of the corpus.
A key step in the LDA modeling process is determining the appropriate number of topics to be extracted from the data. The choice of the number of topics can have a significant impact on the interpretability and performance of the LDA model, as too few topics may fail to capture the nuances of the data, while too many topics can lead to overfitting and poor generalization.
LDA Analysis of Amazon Review Data
This interactive plot provides a 2D representation of the topics extracted using LDA (Latent Dirichlet Allocation). Each circle represents a topic, and the distance between them reflects how semantically different they are.
Key observations:
-
Topic Separation: Topics 1, 2, and 3 are well-separated on the map, suggesting that each topic captures a distinct theme in the Amazon review dataset. For instance, Topic 1 (red) is far from Topic 3 (blue), indicating minimal word overlap.
-
Topic Prevalence: The size of each circle reflects how prevalent that topic is across the entire corpus. In this case, Topic 1 appears to dominate the dataset, while Topics 2 and 3 are slightly smaller in coverage.
-
Top Keywords: On the right side of the visualization, the top keywords associated with the currently selected topic are displayed. For example, if Topic 0 is selected, common keywords include “issue”, “subscription”, “magazine”, “received”, etc., which likely relate to customer experiences with delivery and magazine subscriptions.
-
Interpretation for downstream tasks: This plot helps us understand how distinct the latent topics are, which is crucial for clustering quality, topic summarization, and semantic labeling. A clear separation between topics generally indicates a good topic model.
BERTopic
BERTopic is a clustering-based approach that suffers from limitations such as word representation overload or the generation of only one topic per text.
BERTopic Analysis of Amazon Review Data
This bar chart visualization displays the top-ranked keywords for each topic generated by the BERTopic model. It helps us interpret the semantic structure of each topic by identifying which words contribute most to the topic’s identity.
Key points of interpretation:
-
Topic Composition: Each subplot represents a topic (e.g., Topic 0 to Topic 8), with bars showing the most representative keywords and their associated relevance scores. The longer the bar, the more semantically central the keyword is to the topic.
-
Semantic Themes:
Topic 0 appears to focus on magazines and articles, with keywords like “magazine”, “read”, “title”.
Topic 1 centers around subscriptions and delivery issues, indicated by keywords such as “subscription”, “receive”, “issue”.
Topic 6 seems to reflect positive experiences, including words like “great”, “advertise”, “thank”.
-
Topic Diversity: The chart shows that topics capture distinct themes, from product delivery (Topic 1), holiday gifts (Topic 4), to car-related content (Topic 5). This diversity supports the coherence and separability of the topic model.
-
Use in Clustering: These top words are often used in clustering and downstream interpretation tasks. They provide insight into how customers talk about different aspects of products or services in reviews.
BERTopic: Intertopic Distance Map This 2D scatter plot visualizes the relationships between topics discovered by the BERTopic model. Each bubble represents a topic, where:
-
The size of the bubble reflects the prevalence of that topic across all reviews.
-
The distance between bubbles indicates how semantically similar or dissimilar the topics are.
-
Topics that are close together may share overlapping vocabulary or themes, whereas those far apart are more distinct.
In this example:
-
Several topics (e.g., Topic 0 and nearby clusters) are closely grouped, indicating possible semantic overlap or shared context (such as general magazine content or customer experience).
-
A few topics (top-right corner) are clearly separated, which may suggest niche or highly specific review themes.
This visualization is useful for:
-
Assessing topic diversity
-
Detecting redundant or highly similar topics
-
Supporting topic merging or reduction
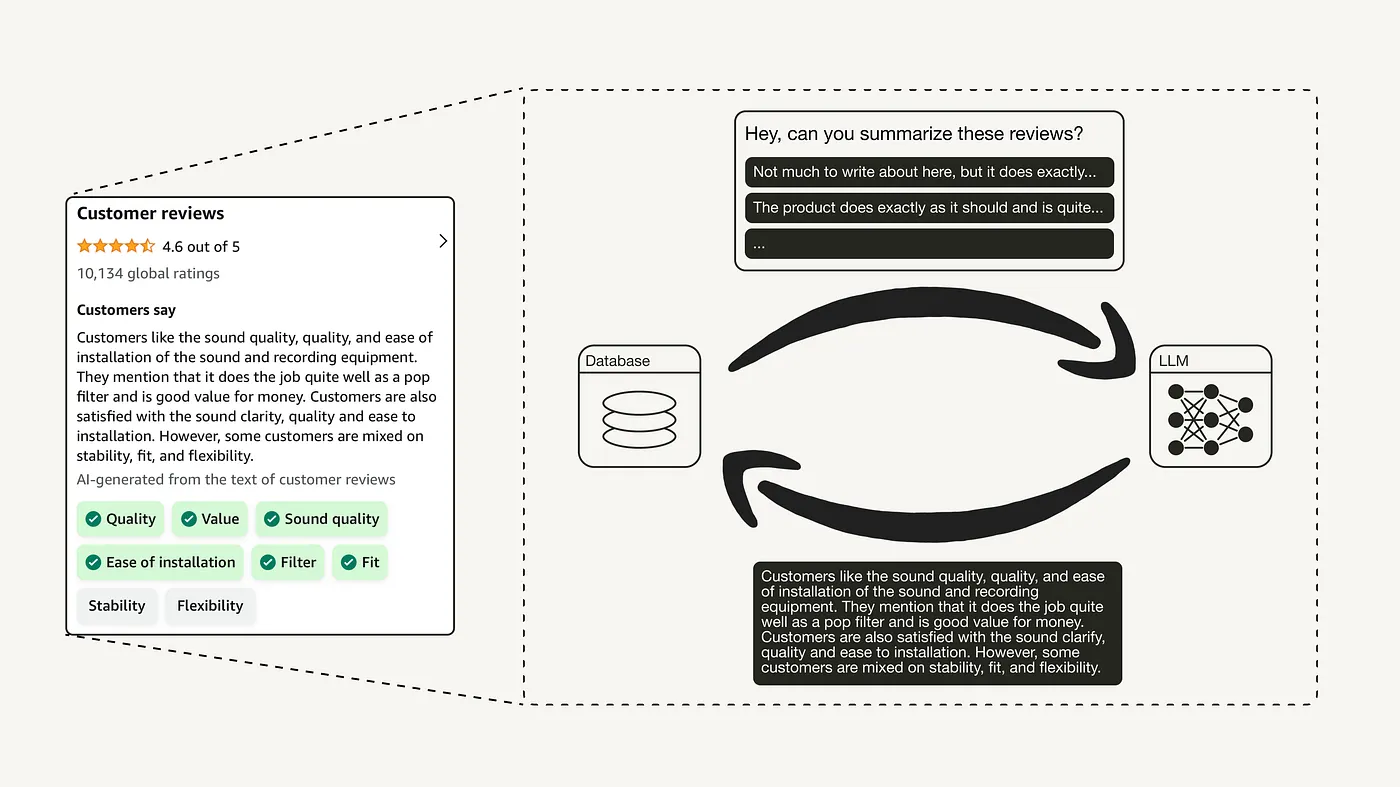
LLM (QualIT)
QualIT: Qualitative Insights Tool is presented in Kapoor et al. (2024) to extend the capabilities of existing topic models. This approach integrates pre-trained LLMs with clustering techniques to systematically address the limitations of both methods and generate more nuanced and interpretable topic representations from free-text data. QualIT complements the analysis step that takes too much time, about 3 months per project, to take one month of a researcher’s time per project.
Unlike traditional topic modeling approaches that rely on hand-crafted features or simple statistical patterns, LLMs can capture complex semantic and syntactic relationships within language, allowing them to better handle the nuances and ambiguities inherent in real-world text.
LLM Analysis of Amazon Review Data
To extract concise and meaningful key phrases from customer reviews, I created a custom function using prompt engineering. This function is designed to guide a language model (GPT-3.5 turbo) to return phrases that best represent the main topics, experiences, and product features mentioned in the text.
# Prompt
def extract_keyphrases(text, index=None, total=None):
if index is not None and total is not None:
print(f"{index + 1} / {total}")
prompt = f"""Analyze the following customer review and extract 5 to 10 key phrases that best represent the core topics, features, sentiments, and experiences mentioned in the review.
Key phrases should capture the main subjects, specific product or service attributes, common issues, or positive aspects.
Guidelines:
- Each extracted phrase must clearly represent a specific point or idea from the review.
- Formulate them as meaningful phrases, not just single words or a list of adjectives/verbs.
- For example: "poor battery life", "excellent customer support", "difficult assembly process".
- Output should be a single line, with key phrases separated by commas.
- DO NOT include explanatory sentences, adjectives, adverbs, verbs, or full sentences.
- The extracted key phrases will be used for subsequent document clustering and topic summarization.
[Customer Review]
{text}
Key Phrases:"""
#return gemini_prompt(prompt)
return gpt_prompt(prompt)
By enforcing phrase-level outputs and avoiding vague words or full sentences, the results are clean, interpretable, and ready for downstream analysis.
Clustering
Top keywords by cluster:
Cluster 0: love / magazine / it / this / like / kids / articles / baby / favorite / granddaughter / grandson / ideas / item / was / loved / loves / new / reading / renew / she Cluster 1: subscription / remainder / published / publication / of / nast / magazine / issues / gourmet / ending / conde / annual Cluster 2: magazine / great / articles / good / reading / to / positive / subscription / and / content / section / enjoyable / read / the / love / received / for / christmas / feedback / experience Cluster 3: magazine / content / and / for / recipes / to / cover / articles / interesting / information / of / editorial / stories / not / quality / cooking / pop / the / yoga / positive Cluster 4: subscription / renewal / magazine / service / customer / issue / delivery / issues / cancellation / amazon / no / to / renew / about / not / for / automatic / experience / pricing / of
Topic Evaluation Metrics (BERTopic)
Coherence Score (N=20): 0.3805
The coherence score measures the semantic similarity among the top keywords within each topic. A higher coherence score indicates that the words in a topic tend to co-occur together in the original corpus, making the topic more interpretable and meaningful.
In this case, the coherence score of 0.3805 is moderate, suggesting that the topics are reasonably coherent, but there may be room for improvement.
This score is influenced by factors such as the choice of embedding model, the number of topics, and how distinct the themes in the reviews are.
Diversity Score (N=20): 0.5444
The diversity score evaluates how distinct the top words are across different topics. A high diversity score means that the topics are not repeating the same words, and each topic brings unique information.
Here, the diversity score is 0.5444, which is relatively low to moderate. This means that while some topics have unique vocabulary, there’s also overlap across topics, which may indicate semantic redundancy or insufficient topic separation.
Thank you for reading!
I hope this helped you better understand topic modeling with LLMs. If you’re curious about NLP, data science, or AI experiments like this one, subscribe and stay tuned for more deep dives!
💡 Suggestions or questions? I’d love to hear from you in the comments!


Leave a comment